Proposals for data ownership are widely misunderstood, aim at the wrong goal, and would be self-defeating if implemented. This Article, first, shows that data ownership proposals do not argue for the bundle of ownership rights that exists over property at common law. Instead, these proposals focus on transferring rights over personal information solely through consent.
Second, this Article shows the flaws of a property approach to personal information. Such an approach magnifies well-known problems of consent in privacy law: asymmetric information, asymmetric bargaining power, and leaving out inferred data. It also creates a fatal problem: moral hazard where corporations lack incentives to mitigate privacy harm. The moral hazard problem makes data ownership self-defeating. Recognizing these deficiencies entails abandoning the idea that property over personal data can achieve meaningful protection.
This Article, third, develops proposals for privacy law reform amidst a national debate on how to formulate federal and state privacy statutes. It argues for a combination of what Calabresi and Melamed call property and liability rules. A mixed rule system is essential because property rules alone fail to protect data subjects from future uses and abuses of their personal information. This Article implements this idea with two recommendations. First, it proposes bolstering private rights of action for privacy harm unattached to statutory breach. Second, it proposes reinforcing ongoing use restrictions over personal data by strengthening the purpose limitation principle, an underutilized ongoing use restriction in American law.
Introduction
Is data ownership a viable way of protecting privacy? The idea that privacy should entail ownership over one’s personal information has gained popularity in legislative proposals,1 the media,2 and academic circles.3 While a broad version of this idea is not new, novel permutations have appeared, for example, in pay-for-privacy,4 data as labor,5 and blockchain.6
This Article engages with data ownership in three ways. First, it revisits and improves popular understandings of data ownership proposals. Second, it identifies a problem that makes data ownership self-defeating. Third, based on that critique, it develops proposals for privacy law reform.
Data ownership proposals contain a conceptual ambiguity. Despite the language that proponents use,7 they have not proposed creating ownership rights over data. Ownership rights (i.e., property rights) constitute closed-form in rem rights. But data ownership proposals do not advocate for implementing this type of right over personal data.
Instead, these proposals advocate for reinforcing consent and creating a marketplace for data that aims to maximize data-subject control over their personal information. Such a market is supposed to extract larger ex-ante compensation for users. The proposals rely not on property rights but on Calabresi-Melamed property rules, which are consequentially different. Property rules stipulate that a right can only be transferred with consent.8 Arguing that rights over personal data should be given away solely by consent refers to property rules—even if some proponents may believe themselves to be applying property rights. One can see this from the language used in the proposals, the absence of ownership rights’ key elements, and the emphasis proponents place on consent, bargaining, and compensation.
In other words, data ownership is usually seen as the view that people should have an ownership right over data. But it is better understood as the view that people should have a right over their data (whatever kind of right it is) protected solely by property rules.9 In clarifying this conceptual ambiguity, this Article refers to these proposals as “data property.”
This clarification shows that data property is subject to criticism on new grounds. Prior scholarship has shown that data property is undesirable because it leaves out important values and dimensions of privacy.10 Understanding that data property proposals defend transfer rules—not ownership—also exposes two sets of problems that have so far not been identified: consent problems and moral hazard.
First, data property relies on—and would magnify the role of—consent in privacy.11 Such reliance on consent, which Daniel Solove refers to as “privacy self-management,”12 has been criticized as fundamentally flawed. Seeing how data property relies on consent makes clear that it inevitably inherits and magnifies consent’s deficiencies: asymmetric information,13 unequal bargaining power,14 and data aggregation.15 Due to these problems, even if data property may seem like it would provide strong protection, it cannot improve data subjects’ vulnerable situation.
Second, understanding data property as transfer rules allows one to see how data property is counterproductive when it comes to achieving its own aim: promoting consumer control. Relying solely on property rules would lead to inadequate and insufficient control because it would eliminate incentives for companies to take efficient levels of care after a data transaction. Therefore, they generate a moral hazard: by not facing the consequences of the losses they produce, companies would have larger incentives to engage in risky uses and disclosures of personal data. This would further reduce people’s long-term control over their personal data and expose them to more harm. This moral hazard makes data property self-defeating.16
This critique informs normative debates in privacy law that do not resort to the language of property but nevertheless share some of data property’s elements by relying on consent. The failures of data property show that ex-post accountability is a necessary condition for robust privacy protection. Privacy law must protect privacy rights with both consent-based rules (which operate ex-ante) and accountability mechanisms (which operate ex-post). Statutory privacy seems to lean too heavily on the side of the former. This Article proposes two ways to address this: (i) combining consent requirements with new private rights of action and (ii) keeping and reinforcing restrictions on the use of personal data.
The first proposal involves establishing private rights of action to enforce privacy.17 Liability responds to the market reality by (i) not relying on unequal bargaining between consumers and companies and (ii) encompassing inferred data. Liability addresses the moral hazard problem by forcing companies to internalize the expected cost of their data use and sharing. Because of these functions, liability can address property rules’ deficiencies in protecting privacy.
The second proposal concerns the importance of reinforcing the controversial purpose limitation principle.18 The purpose limitation principle establishes that personal information must be collected for a specific use and cannot later be given different uses. It is thus the most important ongoing use restriction in statutory privacy. The principle is drawn from the Fair Information Practices Principles, which form the backbone of statutory privacy in the United States.19 But existing and proposed state laws are divided as to whether to incorporate purpose limitation, and it remains unclear whether an eventual federal privacy statute would.
These proposals are particularly relevant now, as states continue to formulate privacy statutes and the federal government considers a (possibly preemptive) federal privacy statute.20 Virginia’s Consumer Data Protection Act (CDPA) and the Colorado Privacy Act, for example, include purpose limitation but not private rights of action,21 while the Nevada Privacy of Information Collected on the Internet from Consumers Act (PICICA) includes neither.22 This Article’s proposals can also be implemented while enforcing these statutes. The usefulness of liability can inform courts when ruling on standing for privacy harms recognized by statute, or when determining whether a statute preempts privacy torts. The proposal over purpose limitation can be used by courts or enforcement authorities (state attorneys general and the Federal Trade Commission (FTC)) in interpreting the scope of purpose limitation and, in particular, when assessing whether specified purposes are narrow enough.
This Article proceeds as follows. Part I provides an overview of data property proposals in legislation, the media, private industry, and academia. Part II shows that most of these proposals refer to property rules, not rights, and thus their key element is about trade (not bundles of rights). Part III outlines how existing criticisms of privacy law apply to data property once interpreted correctly. Part IV explains why data property would introduce an additional, fatal flaw that would lead it to defeat itself: moral hazard. Parts V and VI propose two directions to move past the ameliorated version of the moral hazard problem that exists in privacy law. Part V explains how privacy statutes can complement their property rules with liability rules by creating harm-dependent private rights of action. Part VI suggests reinforcing the purpose limitation principle to better ex-post accountability.
I. The Popularity of Data Property
Data property proposals are increasingly popular. Some of them use the language of ownership with phrases like “you should own your data.” Some use the language of property rights. Others say people should receive monetary compensation when relinquishing their personal information. These proposals are burgeoning in legislation, public policy, general audience outlets, private industry lobbying, and academia.
A. Politics, Media, and the Private Industry
Several proposals in politics, the media, and academia have suggested ownership or property rights over data as a means of increasing data subjects’ control over their personal information and, more generally, their privacy.
Legislation is a good example of this trend. For example, the 2019 Own Your Own Data Act attempted to provide people with property rights over their data, developing a licensing system that focused on portability.23 California has discussed the idea of “data dividends” that rely on property over data.24 Former presidential candidate Andrew Yang has been explicit in his proposal that personal data should be treated as property, meaning that individuals should have ownership over their data.25 Yang claims that, because individuals are not being paid or not otherwise obtaining value for their data, this denies them autonomy and produces a lack of data dignity.26 Yang also started a non-profit organization that advocates for treating personal “data as property.”27
European and Canadian politics have also seen versions of this idea. The Canadian government Committee on Access to Information, Privacy, and Ethics has recommended establishing rules and guidelines regarding data ownership and data sovereignty with the objective of ending the non-consented collection and use of citizens’ personal information.28 More hesitantly, the European Commission launched a consultation group assessing data ownership,29 and former German Chancellor Angela Merkel argued in favor of a uniform E.U. regulation establishing data ownership.30
Similar proposals exist in the media. The Financial Times, for example, argued in 2018 that consumers should be given ownership rights over their personal data.31 The Economist claimed in 2019 that people must own their personal data as a matter of human rights, stating that “data itself should be treated like property and people should be fairly compensated for it.”32 An article in Forbes argued in 2020 that “it’s time to own your data.”33
This idea is not foreign to the private industry either. Robert Shapiro and Siddhartha Aneja, for example, propose that the government and major companies recognize that people have property rights over their personal information.34 Customer data platform Segment is explicit in stating that people should own their data.35 Bird & Bird also developed a whitepaper exploring ownership over data, stating that “new non-exclusive ownership right in data should be created to respond to the EU data economy’s demands.”36 Members of the blockchain community have developed similar proposals, with the idea that blockchain can provide people with ownership over data.37
B. Scholarly Proposals
In academia, the idea of property has repeatedly been proposed as a protection mechanism that could forbid extracting information from data subjects without their consent, hence protecting their privacy.38
Property, the argument goes, would allow for a market for personal information in which each data subject could negotiate with firms regarding which uses they are willing to allow with regard to their personal information and for what compensation.39 By becoming owners of their personal information, according to the argument, data subjects would be able to extract more compensation for its release than they would under a no-property regime, and they would receive compensation for the expected privacy cost associated with each information disclosure.40 Lawrence Lessig famously promoted the idea of privacy as a form of property rights over data to reinforce people’s rights over them.41
More recent proposals tend to suggest some altered version of property to obtain a better fit with the goals of privacy. The recent concept of self-sovereign identity, for example, is aimed at users having complete ownership, and therefore control, over their digital identities.42 Leon Trakman, Robert Walters, and Bruno Zeller argue for intellectual property protection of personal data, highlighting that intellectual property encompasses attributes of both property and contract law.43 Lauren Scholtz and Timothy Sparapani, separately, argue for quasi-personal-property protection.44 Jeffrey Ritter and Anna Mayer suggest regulating data as a new class of property, proposing that regulation of digital information assets and clear concepts of ownership can be built upon existing legal constructs—in particular, property rules.45
In one of its most recent permutations, data property exists under the pay-for-privacy movement.46 Under this movement, there is one element added: The bargaining process triggered by property should lead to financial consideration for personal data. Their underlying idea is that consumers should financially benefit from some proportion of the profits that companies obtain by using their data.47 While building on property, these proposals contain a slight deviation from usual conceptions of private ordering in mandating what type the consideration in the exchange should be.
Related to the above, the latest academic proposal along property lines is Glen Weyl and Eric Posner’s data as labor idea. Contrasting data as labor with data as capital, they call for recognizing the production of data as labor that is done for companies that acquire such data, describing it in ownership terms.48 The personal data that companies profit from is produced and provided by the people to whom that information refers, who are not on those companies’ payroll.49 Data as Labor sees personal data “as user possessions that should primarily benefit their owners.”50 Accordingly, Weyl and Jaron Lanier argued that, because data is a form of labor, taking it without compensation is a form of labor exploitation.51
C. The Descriptive View
In addition to these normative proposals, one often encounters the descriptive statement of “I own my data” in non-technical spaces. European Commissioner for Competition, Margrethe Vestager, for example, stated that “we all own our data. But . . . we give very often a royalty-free license for the big companies to use our data almost to [do] whatever.”52 Canadian businessman Jim Balsillie, similarly, has argued in Parliament that, due to the effects of the European Union General Data Protection Regulation (GDPR),53 people have personal ownership of their data, and such data ownership must be woven into a national data strategy.54 These appear frequently, from overheard conversations on the bus to Reddit.55
These blanket descriptive statements that privacy law grants property over personal data are incorrect.56 In Teresa Scassa’s words, “the control provided under data protection laws falls short of ownership.”57
However, privacy law does contain some property-like elements.58 The same is true of most proposed bills; as Julie Cohen notes, “none of the bills recently before Congress purports, in so many words, to recognize property rights in personal data. Even so, almost all adopt a basic structure that is indebted to property thinking.”59 For example, consent is a central element of all federal privacy bills currently before Congress, as it is in some state acts such as the California Consumer Privacy Act (CCPA), the Colorado Privacy Act, and Virginia’s CDPA.60 Data property proposals involve moving the dial further toward these property elements and away from consent-independent restrictions and guarantees.
These descriptive statements show that, because of the property-like elements in current privacy law, data property critiques inform privacy law reform. Under current law, one may transfer rights over personal information through consent, but one may not relinquish all rights regarding personal information. Certain uses of this information—such as use for public shaming—remain prohibited regardless of what people agree to. These restrictions speak against conceptualizing privacy rights as transferable, property-like commodities under current law. While this Article is concerned with normative and not descriptive views on data property, the descriptive view underscores something important: The negative consequences of moving privacy law all the way to consent-based protection can inform whether privacy law should actually move one step toward the opposite direction.
II. What Data Property Really Means
As readers may have noticed, data property proposals have something in common: aiming for people to control their personal information by choosing when to give it away and having the ability to agree on compensation for it. However, this has nothing to do with ownership, and everything to do with transfer.
A. Rights and Transfer Rules
Privacy law establishes rights (entitlements) and their corresponding obligations over personal information.61 But together with establishing rights, the law regulates their transfer.62 Granting a right and establishing its transactional structure are independent operations.63 Rights’ transactional structure determines under which conditions valid exchanges (transactions) over those rights happen.
The law establishes transactional structures by placing transfer rules over rights.64 Under the Calabresi-Melamed framework, there are three types of transfer rules: property rules, liability rules, and inalienability rules.65 Rights protected by property rules are transferred with the title-holder’s consent and in exchange for a price determined through bargaining.66 Examples of these are everyday contracts. Rights protected by liability rules are transferred without the title-holder’s consent and in exchange for a judicially determined price.67 Liability rules are used mainly due to high transaction costs of ex-ante bargaining—or an actual bargaining impossibility.68 For example, if a factory pollutes in breach of environmental law, it will have to pay compensatory damages—not restitution. Rights protected by an inalienability rule are not transferable, and if the transfer somehow takes place, the law sets back or nullifies the transfer to the extent possible.69 For example, an agreement to sell an organ will be rendered void.70 Property rules, liability rules, and inalienability rules thus define the transactional structure of the rights they protect, whichever those rights are.71
Ownership—also called property rights—is different than property rules. Property rights (ownership) are a set of rights over a thing. Depending on the theory of property one follows, ownership can be conceptualized either as a specific bundle of in rem rights (rights over an object opposable to the whole world) or as dominium over a thing.72 In the first position, the set of ownership rights include, for example, the right to use, exclude, sell, possess, subdivide, and lease. In the second position, ownership is a relationship between people in relation to a thing with the key characteristic of omnilaterality.73
The right of ownership right (or a property right) is a type of right that can be protected by any transfer rule: property rules, liability rules, or inalienability rules.74 In contrast—in an unfortunate ambiguity—property rules are a transfer rule based on consent that can be used for any type of right.75 It may be the case that the more one conceives an entitlement as a property right, the more favorably one will tend to look at property rules and the less that one will tolerate liability rules; for example, the ownership right has few liability rules. Rights over real property are frequently protected by injunctions while contractual rights are frequently protected by damages.76
But this correlation does not collapse the conceptual distinction. For example, eminent domain is a liability rule over an ownership right over one’s land. Buying the land, on the other hand, is a property rule over the same ownership right. Receiving compensation for environmental harm is a liability rule for something (the environment) over which one does not have ownership; receiving compensation for a bodily injury is also a liability rule over something (one’s body parts) that cannot be described as ownership. Subletting a room in an apartment is a property rule over something one does not own. Similarly, transferring rights over data only by consent and on an agreed upon compensation is a property rule over something that one needs not have ownership over. Individuals do not need to hold a property right (ownership) in data in order for the transfer of whichever rights they have over it to occur via property rules.
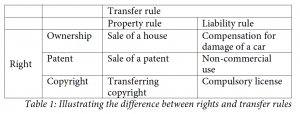
Based on this distinction, one can evaluate whether property rules, liability rules, or inalienability rules are the best way to regulate the transfer of the right to collect, use, or share personal information. While inalienability rules are uncommon and their justifications vary,77 the law frequently alternates between property and liability rules.78
To the extent that the law protects privacy through property rules, the right-holder (data subject) will have the right to decide who can collect, use, or share her personal information and who cannot, hence excluding others from the information. To the extent that privacy interests are protected by liability rules, the right-holder will have a right to be compensated whenever someone accesses, uses, or shares her personal information in a harmful way. Privacy interests are protected by both property and liability rules. The most meaningful question is not which one should be chosen to govern privacy, but rather where on the privacy-to-liability spectrum personal information is best protected.
Consent follows property rules. Broadly speaking, “[u]nderstood as a crucial mechanism for ensuring privacy, informed consent is a natural corollary of the idea that privacy means control over information about oneself.”79 The consent-reliance argument defends the use of property rules for people’s personal information, which, under this rule, is collected, processed, and distributed, chiefly based on consent.
Placing property rules (due to the ambiguity explained, sometimes misconstrued as ownership) over personal information has been defended on the grounds that it would force a negotiation that would benefit data subjects.80 Property rules, the argument goes, would allow for a market for personal information in which each data subject could negotiate with firms regarding which types of collection, use, and distribution they are willing to allow with regards to their personal information (or each type of information).81 Data subjects, moreover, would be able to extract ex-ante compensation for its release,82 and they would receive compensation for the expected privacy cost associated with each information disclosure.83 While this appears desirable, there are severe problems with this approach, described in the next Part.
B. Data Property Is About Transfer, Not About Rights
When people in politics, the media, the industry, and academia refer to data ownership or to privacy as property, they have largely not proposed to establish a new type of right, but a transfer rule.
Recall that a property right (ownership) is a type of right that can be regulated by any transfer rule.84 Property-rule protection of personal information amounts to a non-collection default that applies unless consent is given.85 Property rights often (but not always) have a transactional structure established by property rules. Sometimes, property rights are forcefully “transferred” by liability rules. For example, if you break someone’s widget (over which she has personal property) without her consent, as a consequence you must thus pay her a compensation that will be determined by a judge. This amount will not necessarily be the amount that she would have agreed to sell you the widget for.
Arguing that personal data should be subject to a property right could take either of two forms. It could take the form of an argument that personal data should have the same bundle of in rem rights as ownership rights do. Or it could take the form of an argument that personal data should have the main characteristic of ownership: the in rem right to exclude others from the thing over which one has property.86 In either conception of property, a property right for data would be numerus clausus, which is the principle according to which there is a closed form list of property rights.87 This is not what data property proposals suggest.
Data property proposals emphasize consent as the valve to authorize giving information away. As a consequence, they rely on any agreed-on ex-ante compensation for personal data and not on the particular bundle of rights that is ownership over conventional property (real or personal). In other words, these proposals do not suggest that the right to privacy should be shaped differently—i.e., that a bundle of rights akin to conventional property should be assembled to replace existing privacy rights. They instead suggest that the rights that data subjects hold over their personal information (privacy rights) should not be transferred without their consent or for a socially established compensation, but rather with their consent and for a bargained-for compensation. Transfer by consent, however, is not unique to property rights. Most academic and policy discussions of data property do not discuss the nature of an entitlement (right) but rather how that entitlement is transferred in the marketplace—and that there should be a marketplace for it to start with.
Many of the proposals described above exemplify this idea.88 Jane Baron discusses data property as a tool to give people control by providing them with choices.89 Raymond Nimmer and Patricia Krauthhaus argue that “[p]roperty rights in information focus on identifying the right of a company or individual to control disclosure, use, alteration and copying of designated information.”90 The report to the Canadian House of Commons focuses on doing away with non-consented collection and use.91 Yang’s proposal focuses on allowing individuals to “share in the economic value generated by their data,”92 but the way value is shared depends on the transfer rules and not on the type of right. Likewise, several blockchain proposals focus on control, with statements such as: “Blockchain is set to change data ownership. It will help restore data control to the user by empowering them to determine who has access to their information online.”93 And control depends on the mechanism through which rights are transferred.
This extends to proposals that explicitly use the language of ownership rights. For example, van den Hoven explores ownership as a means of maximizing data subjects’ control over their personal information,94 even though the type of entitlement does little to enhance the right-holder’s control over it—the transfer rules do. Ritter and Mayer, similarly, propose a system of ownership to establish control over transfers.95 But the type of right does not determine whether it is transferred with or without consent—the transfer rules do. Thus, most who claim that privacy rights should transform into ownership rights err in that, without specifying the transfer rule, this identification does not arrive at the kind of protection that they seek.
Some scholars have hinted at this mischaracterization. Cohen’s critiques, for example, apply to property rules. Scassa, similarly, has said that “[a]lthough the personal data economy is burgeoning, it appears to be based more on contractual models than on any underlying ownership right in personal information.”96 Václav Janeček and Gianclaudio Malgieri have described the tradability distinctions in terms of res in commercio and res extra commercium, refraining from property language.97 But the mischaracterization, which is consequential for how one should address these popular reform proposals and how one should address elements of property in privacy law, remains.
The exclusionist conception of property rights, because it focuses on the ability to exclude (and exclusion must be done through an assertion, which expresses consent),98 rings similar to property transfer rules. This may be a source of confusion. There are, however, two important doctrinal differences. The first is that property rights are in rem and are numerus clausus, but transfer rules are not. Data property proposals, as shown above, have neither of these two characteristics. The right to exclude is, in turn, insufficient to transfer the right. For that, one needs the right to alienate—a separate right of the bundle.99 Conceptualizing data property proposals as suggesting a right as opposed to a transfer rule would thus include two things that the proposals do not argue for (in rem and numerus clausus) and lack the main thing that the proposals argue for (control exerted through consent-based alienation).
This in rem characteristic would be patently problematic for personal information. Neither under existing law nor under data property would I have a right, for example, to prevent other people from noticing I bought a banana when I went to the supermarket. But I retain a right under both on whether the store owner can enter the information into a customer data bank to then sell to third parties. Both rights (the one I lack and the one I have) refer to the same information—that I bought a banana. The right is not in rem because it does not accompany the information neither under existing law nor under data property. The right is also not omnilateral, neither under existing law nor under data property, because it depends on the relationship between me and each person regarding the information.
Ensuring a specific means of transfer (i.e., through consent) is the purpose of transfer rules, but it is a corollary of the exclusion right. This conceptual difference is somewhat unimportant for physical objects, where use and transfer are dissociated clearly: I can lend you my soccer ball while retaining my right to exclude you from it. With information, transfer and use get muddled:100 letting Google use my personal information strikes similar to transferring rights over my personal information to Google. Because use and transfer are muddled in personal information, distinguishing the exclusion right in the bundle of rights that is ownership from property rules for transfer is more important than it is for physical objects, as it is needed to prevent abuses.
In sum, when people have proposed establishing property over data, they have discussed the implications of having data protected solely by property rules, and not necessarily by ownership. One can see this from the language used in scholarship, policymaking, industry, and media—in particular due to the emphasis placed on consent. The view is usually criticized as the view that people should have an ownership right over data, but the view is better understood as the view that people should have a right over their data, whatever kind of right it is, that is protected by property rules. As the next two Parts explain, this view is objectionable on different grounds.
C. Inadequate Goal
Data property, which seeks to promote data subjects’ control over personal information, has been criticized for pursuing the wrong goal.101 This is because privacy is about more than individual control. As Lisa Austin argues, even Alan Westin, often read as the paradigmatic defender of privacy as control, does not support a narrow, control-only definition of privacy.102
Ultimately, privacy is necessary for protecting people’s autonomy. A lack of privacy can lead an individual to feel that they are under surveillance or scrutiny by others.103 As a result, their spectrum of thoughts and behaviors may be tailored to those that they perceive others consider acceptable, thereby limiting their freedom to develop as an autonomous person.104 The importance of privacy for autonomy leads privacy to be central to citizenship.105 Privacy, thus, is more than individual control over information.
Cohen argues that property cannot support a broad conception of the protection of privacy.106 Data property would lead individuals to focus, above all things, on their “surplus in the marketplace,” which is contrary to U.S. constitutional values, which establish “robust privacy protection for thought, belief, and association.”107 She indicates that property is an undesirable means of privacy protection to the extent that the thing that is owned (data) is equated with tradability.108 But, unlike other market goods, personal information is part of people’s personhood.109 Relatedly, data property has been said to raise constitutional issues, particularly in terms of speech.110
Protecting privacy beyond a market for personal information is crucial for respecting individuals.111 Elettra Bietti, for example, argues that “ownership creates a market over data as a commodity and entails a specific kind of harm: that of severing the self from personal data as an object, allowing monetization and trade over such object, and obscuring the losses in human dignity or integrity that result.”112 For that reason, she argues that shaping the data economy through transfer and acquisitions is reductive.113 Jane Bambauer, similarly, demonstrates that data ownership and a market to disseminate personal information would not work because personal information is nonrivalrous and its value is difficult to predict.114
Equating data with tradability is what property rules—but not property rights—do. Together with these other critiques, Cohen shows, in other words, that data property proposals pursue the inadequate goal of individual control. Because Cohen’s critique focuses on the problems of tradability, it problematizes the application of property rules to personal data. As I showed above, this is what data property proposals suggest. These critiques therefore apply to data property proposals (as reframed), and not only to the strawman of creating ownership rights over personal data.
Privacy scholars have correctly argued that data ownership faces important problems in critiques that extend both to ownership rights and to property rules. Viewing data property for what it is allows one to see two additional things: that data property inherits the problems of consent and that it also defeats itself.
III. Why Data Property Is Ineffective: Old Reasons Applied to New Ground
Once one understands data property proposals for what they are—relying on people to self-protect and compensate privacy based on agreements, independently of eventual harms caused—one can see that several criticisms directed at privacy law’s reliance on individual consent also apply to data property, exposing equivalent flaws.
Because of its focus on trade (relying solely on property rules), data property creates three structural problems in the protection of privacy rights. First, it inherits the notice and choice model’s asymmetric information problem. Second, and relatedly, it becomes ineffective at protecting privacy due to unequal bargaining positions. Third, it under-protects personal information derived from data aggregation (inferred information). These structural problems are discussed in the following three Sections.
A. Asymmetric Information
The last Part showed that data property is not concerned with the type of rights held over personal information but rather with transferring them through consent.115 For that reason, the limits of the notice and choice paradigm translate into data property. Although this Article is not about the benefits and limits of consent in privacy, notice and choice’s asymmetric information problem is relevant because data property inherits it.116
There is, at a broad level, an information asymmetry problem between data subjects and data processors that makes consumers vulnerable.117 Data subjects lack the technical knowledge necessary to sufficiently understand terms and conditions.118 Moreover, understanding them, let alone bargaining over them, would take an enormous amount of time.119
Solon Barocas and Helen Nissenbaum have said that “[b]ig data extinguishes what little hope remains for the notice and choice regime.”120 While many call for more companies to implement consumer privacy notices as a way to increase transparency,121 others suggest that notices are ineffective at increasing consumer awareness of how their personal information is managed, even if they are simplified and even if people read them.122 Empirical evidence has shown that simplifying disclosures has no effect on consumer awareness, suggesting that language complexity is not the main driver.123 Moreover, other empirical work suggests that the language used in a privacy policy is irrelevant, which in turn suggests that consumers do not react to different kinds of language.124
This limitation on the usefulness of notices may be due to information overload.125 That is, it may be the case that the reason why notices are rarely effective is that, no matter how simply formulated or visible they are, there are too many cognitive steps between the information disclosed (e.g., geolocation tracking) and the information that is useful (e.g., does anyone know where I go and who I spend time with?).126 For example, while people do not respond to privacy policies, they have been shown to more easily respond to and understand information conveyed by design choices.127 Information overload is worsened by the problem of data aggregation discussed below because one of the main drivers of consumers’ difficulty to estimate costs is anticipating how information aggregates.128
Beyond descriptive criticisms about the effectiveness of the notice and choice approach, it has received normative criticisms based on the dynamic between companies, the State, and individuals.129 From a structural perspective, the approach has been criticized for over-focusing on each individual (“it is up to me to decide what information about me I want to share and with whom”).130 As a consequence, the argument goes, the approach insufficiently addresses legitimate countervailing interests. Sometimes, privacy interests can yield to other interests—such as containing a pandemic. The consent-based approach addresses this by formulating exceptions for them—such as public interest exceptions. But the formation of obligations for entities who must obtain consent to collect or process personal information in a way that is context-independent fails to appropriately recognize interests that are not the individual’s.131
Because data property depends on consent and control, the asymmetric information criticism of the notice and choice system extends to the reliance on consent by property rules.132
B. Unequal Bargaining Positions
A second limitation of data property is that it assumes that data subjects’ expressions of consent means that they are able to manage their privacy risks. Even if they are fully informed, data subjects will rarely be able to manage their privacy risks because of the unequal bargaining power between them and companies.
Due to the type of interactions in which privacy policies are involved, where data subjects have limited options, it is at least questionable to believe that reinforcing property rules would improve data subjects’ bargaining position.133 Under property rules, data subjects frequently face a take-it-or-leave-it option between either using a product and giving their personal information for free, or not using the product at all.134 If they need to use the service, for example, because using it is part of normal social life and therefore costly to opt-out of it, such as with email or a cellphone provider, this consent is not given freely.135
This relates to the idea of privacy self-management, under which people manage their own privacy in making decisions about when and how to give away their personal information.136 The privacy self-management model is predicated on the false premise that informed and rational individuals will make appropriate decisions as to the use and collection of their personal data.137 This model fails to address the unequal bargaining positions between data subjects and information intermediaries, as well as the data aggregation problem explained below.
It is impossible for data subjects to properly assess the risks involved in disclosing their personal information in the digital environment.138 Data subjects cannot assess the risks of disclosing because they do not always know how their data will be used and what can be done with it.139 Some also argue that data processors even have economic incentives to mislead data subjects, which adds to the problem.140 As Maurice Stucke and Ariel Ezrachi explain: “Under the . . . opaque system, there’s no way of knowing whether we’re getting a fair deal. We have little idea how much personal data we have provided, how it is used and by whom, and what it’s worth.”141 The costs of assessing risks when providing consent are enormous.142
Accordingly, Neil Richards and Woodrow Hartzog argue that digital consent is only valid when choices are infrequent (to prevent choice overload), the potential harms are easy to imagine (so that consent is meaningful), and consumers have reasons to choose consciously and seriously (so that consent is real).143 And digital consent over privacy rarely meets these conditions.144 It is difficult to believe in this context, even with the efforts on reinforcing meaningful consent, that data subjects could make informed and welfare-enhancing choices.145
C. Aggregated and Inferred Personal Data
Another problem is that personal information is inferred by aggregating data; that is, by compiling different types of information provided by the data subject, perhaps to different companies, at different times. This information is under-protected by property rules. This is because risks of aggregation are impossible to estimate, as scaling effects make the sum of disclosures unequal to constituent parts of disclosures.
Even if there were adequate information and no obstacles to how freely consent is given, data subjects under data property would receive ex-ante compensation only for providing consent for each piece of information released to each data collector. However, they would not have ex-ante compensation for the inferred information, which is more valuable and potentially more harmful.146
Taken individually, most data points shared might not even be valuable enough to induce companies and data subjects to bargain over them.147 But, combined, the same data points present high risks to users.148 And the way that information aggregates, as well as how high these costs are, are extremely difficult for data subjects to anticipate.149 People lack protection for the risks of disclosing personal data if they are given small compensations for each disclosure while they face high expected harms for them in aggregation.150
Two recent cases illustrate this dynamic. In Meyers v. Nicolet Restaurant, a restaurant allegedly violated the Fair and Accurate Credit Transactions Act (FACTA) by printing the expiration date of a credit card on a sales receipt.151 In Kirchein v. Pet Supermarket, a supermarket printed more than five digits of credit card numbers on customers’ receipts, which is a violation of prohibitions on printing more than the last five digits of the credit card number or expiration date on the receipt provided to the customer.152 In both cases, the plaintiffs alleged that the company increased the risk that the customers’ identity would be compromised, for example through identity theft. Printing a full credit card number instead of the last four digits, or printing the expiration date together with the last four digits, may seem harmless in isolation. But, if businesses are not sanctioned for breaching FACTA in such a way and a malicious actor can hack the systems of a few restaurants, because of the aggregation problem, it may be easy for them to duplicate credit cards. If that happens, it will be difficult for customers to trace back the duplicated credit cards to the aggregation of different pieces of extra credit card information from the different restaurants.153
Another extension of the inference problem is that personal information is inferred not only from the information that each individual releases but also from information provided by or taken from others. Data about different people are routinely combined.154 My consent to collection and usage of data about me can be used to inflict harm on others when combined with their own shared information.155 Consent of any person becomes irrelevant as one aggregates people to the dataset and infers, probabilistically, personal information about each person based on what was disclosed by others.156 Under a data property model, each individual is a prisoner of other people’s choices.
That has led some to characterize personal data as a public good.157 In other words, information is not a distinct commodity because it can be held by several agents at the same time. Every decision about personal data has spillover effects on others.158 This has led some commentators to characterize personal information as a commons, where personal information exchanges generate negative externalities towards others who are impacted by the exchange indirectly in a way that is not captured by property rules.159 And information is relational, in that it relates to more than one person. Examples of these characteristics can be as simple as a group photo or as complex as a database to train a machine learning algorithm. No data is only about one person.160 These characteristics make personal information unfit for in rem rights and for individual-consent-based property rules. A consequence of our information’s informativeness about other people is that property itself becomes difficult to allocate appropriately, as several data subjects may have a claim over a single piece of information.161 Trying to square data property, which would give exclusion rights to each “owner,” with something as simple as a group photo, shows that stating that someone “owns” data is at odds with the idea that privacy is about governing appropriate information flows162—the power to exclude cannot be given to everyone involved in the information.
An extension of this problem is the under-protection of de-identified data.163 Privacy statutes do not protect data without identifiers. But so-called anonymous datasets hold enormous power, and they can cause group harms. Even data that is kept anonymized is informative of individuals in the aggregate. Thus, it can be harmful to individuals because it is informative about groups that they belong to, allowing inferences for members of such groups.164 For example, if a company has information about people’s sexual orientation and it also has aggregated probabilistic information about preferences and behavior of queer individuals, then it knows more about each queer individual than if it only had the former.
Moreover, data can always be re-identified.165 Data property cannot require compensation upon re-identification because its protection exists only at the moment of transfer. Consent-based rules, therefore, under-protect data that are obtained while being anonymized, which then can be de-anonymized, becoming harmful. This includes both the privacy harm that re-anonymization involves per se and the consequential harms that can accrue from it.
From a process viewpoint, the idea of data as labor diverges here because it validates control over inferred data by data aggregators by arguing that, because they invested labor into creating it, they are more deserving of having control.166 That is, the lack of protection for inferred data is not a bug but a feature of the data as labor idea. This does not invalidate the aggregation-based normative criticism towards it. Moreover, even under the data as labor idea, most pieces of inferred information that someone contributes to will also have had contributions by others, creating simultaneous claims or at least the curtailing of some property rights by other people’s incompatible claims.167
Personal data, in other words, is about inferences.168 Even if it were true that data subjects made informed and free decisions about their data, companies would infer information about them based on the information that they have about others; that is, information that others have consented to disclose but the data subject has not.169
In sum, data property would not protect against data aggregation. That is so because it would not provide control over inferred information—created by assembling previously collected information—and would be impossible to allocate appropriately for information that is relational.
Consent-for-use is the system already in place for privacy,170 and privacy scholars have shown that it is ineffective. Data property, by placing further weight on consent-for-use, would not improve the status quo. A regime that relies only on property rules would mean that companies would be able to use individuals’ data when those individuals consent to the use. But consumers already do this when they consent to websites’ and apps’ terms of service. The ineffectiveness of data property is not theoretical—it is actualized.
IV. Why Data Property Is Self-Defeating
In addition to exacerbating these pre-existing problems,171 data property contains a fatal flaw: it produces moral hazard. In contrast to existing property criticisms, which show how data property tries to achieve the wrong goal,172 and newly applicable criticisms, which show that data property is ineffective at protecting people’s privacy,173 the moral hazard problem means that data property is counterproductive at doing the very thing it tries to do: increasing user control.
A. Moral Hazard in Privacy Law
In January 2021, queer dating app Grindr faced a historic fine of ten percent of its global turnover by the Norwegian Data Protection Authority.174 The fine arose from having inadequate consent provisions as to what information it sent to third parties. A take-it-or-leave-it option in its privacy policy, the Authority ruled, was insufficient given the information’s sensitivity, which includes sexual orientation and HIV status.175 Similarly, in Frank v. Gaos, Google allegedly leaked information about users’ search terms to third parties, providing websites with users’ personal information, as well as informing them of the search terms that led users to their website.176 The plaintiffs alleged that the collection and unauthorized disclosure led to feelings of being under surveillance. Why was Grindr and Google users’ well-being affected after they had agreed to a policy that authorized both practices? Because of privacy law’s moral hazard problem.
Moral hazard takes place when someone (in this case, a company that collects or processes personal data) has incentives to increase risk for someone else (in this case, consumers) because they do not bear the cost of such a risk increase.177 Although moral hazard is frequently explained in terms of insurance, it is much broader: in economic terms, for the purposes of moral hazard, “‘insurance’ is provided any time that one party’s actions have consequences for the risk of loss borne by another.”178 Particularly, limiting liability falls within that broad conception of insurance.179
Legal scholars have proposed solutions for moral hazard across several areas of the law.180 A common type of moral hazard is the principal-agent problem, where the behavior of one party (the agent) affects the well-being of the other party (the principal) and there is asymmetric information about the behavior of the former (the principal has limited knowledge of the behavior of the agent).181 The agent then has incentives to either invest lower amounts of effort than optimal (which economists call “slack”) or act in a way that is beneficial to him but not in the best interest of the principal (which economists call “expropriate”).182
Moral hazards are what economists call an ex-post information asymmetry problem: it happens after the interaction takes place and because one of the parties (in this case, the consumer) has little information about what the other parties (in this case, the companies) do.183 If both parties could know in advance and be able to observe the agent’s risk-taking behavior following the interaction, they could try to add a contractual clause that internalizes the risk.184 But one of those parties (in this case, the consumer) is unable to do so because of the information asymmetry.185
Because one of those parties (the consumer) does not know when the other party (the corporation) engages in risky behavior, the second party (the corporation) has incentives to take more risk than the first party (the consumer) would agree to.186 This is a problem in areas where the first party’s well-being is affected by the second party’s behavior after the interaction. In particular, it is a problem when the second party’s care can reduce the amount of harm to the first party, they can control their level of care, their liability does not depend on their level of care, and they are expected to behave rationally.187
2. Perverse Corporate Incentives
Scholars have considered this lack of incentives to take care ex-post as a drawback of property rules in other areas of the law where parties are affected by the interaction after the fact. For example, this is the case in environmental law for the calculations of carbon dioxide emissions.188 When there is a lack of ex-post restrictions and monitoring, companies have incentives to take environmental risk to minimize private costs, such as those created by environment-preserving measures; costs are then externalized to the general population in the form of pollution.189
This moral hazard problem would further interfere with interactions between data subjects and corporations if the sole mechanism to transmit the rights over information processing were consent, as it would be under data property. Once information is collected, under a sole-consent rule the data collector has full control over the information. The uses and disclosures of the data, however, continue to affect the data subject’s interests and well-being, as the Grindr case and Frank v. Gaos illustrate. This is because personal information inevitably retains a connection to the person even after they no longer control it.190
Corporations have, therefore, incentives to do two things. First, they have incentives to under-invest in care as long as they comply with external boundaries, such as cybersecurity regulations, increasing the risk of data breaches ex-post (in economists’ terms, slack). For example, when encrypting, they have incentives to use minimal encryption that is easier to implement but also easier to override.191 This is because the cost of any safeguards is borne by corporations, while safeguards’ benefits are received by data subjects in the form of reduced risk. Thus, there is no economic reason for corporations to implement these safeguards other than compliance with regulations or a tenuous benefit over competitors from a reputation standpoint.192
Second, corporations have incentives to engage in high-risk activities independently of the risk that those activities create for data subjects, consequently driving up harm (in economists’ terms, expropriate). For example, they have incentives to give personal data risky uses that are not in the best interest of data subjects, such as aggregating de-identified data to a point where it can be easily reidentified, or giving it away for profit, as in the Grindr example above. In the same way that the cost of safeguards is borne by corporations and the benefits accrue to data subjects—resulting in too few safeguards—the cost of further processing is borne by data subjects in the form of increased risk while the profit opportunities exist for corporations—leading to too much and too risky processing. If the benefits and costs of processing data (or enacting safeguards) were borne by the same entity, an adequate level of processing (or safeguards) could be reached. But data property cannot guarantee this.
B. How Data Property Would Make Market Failures Worse
1. Magnifying Existing Market Failures
A diminished version of this market failure exists in privacy statutes to the extent that they contain property rules by relying on consent at the moment of collection as a protection mechanism (a property-rule characteristic). This problem arises because property rules are satisfied only at the point of transfer, allowing the acquirer to ignore potential externalities later on. This can be contrasted with liability rules, which can impose costs after the transaction.193
The market failure would be aggravated if the law relied on data property for data subjects’ protection, moving the dial further away from liability rules and into data property’s exclusively-property-rule protection. If data collectors must only compensate data subjects to obtain consent to collect their personal information (for example, by providing them a service), then companies have no incentives to incur costs of care or to moderate activity levels (information processing) to avoid risk to data subjects. These are data externalities.194
This market failure would defeat any permutation of data property even if data subjects had perfect information, were fully rational, and could engage in capable privacy self-management—which is not the case. This is so because moral hazard does not arise from an agent failure: it arises from a combination of a party’s level of risk-taking after the interaction affecting the well-being of the other and a structural lack of incentives for that party to take the other party’s interest into account after the exchange. For that reason, it would be impossible for data subjects and companies to anticipate the magnitude of the moral hazard and factor it into a price for data. Prices simply cannot set adequate incentives ex-post.
Moreover, even if data subjects had full information and could calculate the expected externalities into their compensation for data, this would not solve the problem because companies would continue to lack incentives to invest in care to minimize data subject risk ex-post. If users under data property were rational, they would anticipate this increase in risk and increase the “price” demanded for their personal information in accordance with the increased risk.195 The price increase would reduce the demand for such information in equilibrium, which would reduce the supply of information to meet that demand.196 This moral hazard problem would, in turn, make the market unravel. This, of course, has not happened, but not because the market failure does not exist but rather because, as the last Part explained, data subjects do not make fully informed choices, so they cannot adjust for expected risk.197 In other words, the market does not unravel because data subjects often unknowingly make welfare-decreasing decisions.
The measures that are beneficial for data subjects, but which companies lack incentives to incorporate under a property regime, are different. These measures could be cybersecurity protections to prevent data breaches. Arguably, cybersecurity regulations mandate these protections because consent-based privacy regimes are ineffective at encouraging them. These measures could also involve avoiding risky or harmful uses of data. They could also be, for example, encouraging sufficient de-identification of data. Many activities may increase expected harm for data subjects more than they increase expected benefits for companies processing data, but companies have incentives to engage in the socially inefficient behavior because they can externalize this cost.
2. Transaction Costs in Privacy Under Moral Hazard
Economics-minded readers may wonder: if property rules are usually suggested for scenarios with low transaction costs, and the internet reduces the cost of communications (and therefore the cost of transacting, keeping all else stable), why do property rules fail to accomplish their goals in privacy?
To answer this question, one must consider that the real “cost” of someone’s personal information, from that person’s perspective, is not the cost of communicating the information. Rather, it is the expected harm of having their information processed, such as possibly being discriminated against, or having their information disclosed, such as having their identity stolen after a breach. The more personal information is processed, the higher the expected harm. Even absent the moral hazard market failure, for a property-rule-only system to work, data subjects would have to know the expected harm of their information in advance to ask for an equivalent price and receive compensation.198
Privacy harm often involves several potential parties who are unidentifiable ahead of time, many of whom only come into contact with the data ex-post.199 Negotiating over one’s information thus has high costs, even when communication costs are low. For this reason, the transaction costs of protection are more relevant than the transaction costs of communications to set a transfer rule for privacy rights.
Moreover, these transaction costs are not equally distributed. They are astronomical and unpredictable for those that are disadvantaged in society, who have fewer options and fewer means to protect themselves. This fact adds a distributional concern to the efficiency concerns of data property. Because of their lack of options, the people for whom transaction costs are higher are precisely those that, under property rules, are the least empowered to improve their situation.
In sum, unlike things that are subject to personal or real property, personal data have the capacity to affect the data subject’s interest after transfer. Data property can protect from some wrongful collection, but not from wrongful use or wrongful sharing, and many of the harms related to privacy occur at these two stages. This continuity makes property rules a bad fit for personal information.
V. Expanding Private Rights of Action
Data property, as demonstrated, would create a property-rule-only regime that fails to address the moral hazard problem. Some elements that make data property undesirable are already present in American privacy law (e.g., primacy of consent, bargaining issues, companies not taking on externalities). In addition to avoiding a negative privacy law development towards data property, understanding why data property is undesirable can help improve existing and proposed privacy statutes. Dependence on property and liability rules exists on a spectrum. For any right (including privacy rights), legislators need not choose between all-property rules and all-liability rules. Since property rules are insufficient to protect individuals’ personal information, liability rules must be used to address the problems presented in Parts III and IV.
Liability rules allow for ex-post compensation based on harm; and the risk of that harm depends on the corporation, not the data subject. Liability addresses moral hazard because it leads corporations to internalize such risk. Liability also compensates data subjects for the resulting harm and not just for a value negotiated or determined at the time of collection.
These liability rules could be implemented through tort law or statutory private rights of action. Private rights of action are not a guarantee in statutory privacy, but they should be. These are absent from Virginia’s CDPA.200 Nevada’s PICICA and the Colorado Privacy Act explicitly reject them.201 They are limited in the CCPA and the California Privacy Rights Act, available only in case of a security breach.202 And they are implemented by some, but not all, proposed state bills.203 Broadly, liability is highly controversial in statutory privacy.204
A. The Benefits of Privacy Liability
1. Addressing Property’s Problem
There is a clear benefit of incorporating liability transfer rules in privacy law to address moral hazard. Under liability rules, consent is not a prerequisite for the right’s transfer. This may seem counterintuitive as a means of protection; when protected by liability rules, data subjects would be unable to block a company from using personal information. Liability rules do not aim to increase control. They aim to prevent and remedy harm when control is impossible.
Instead of “choosing” whether to allow processing and suffer future consequences, under liability rules data subjects would be compensated if any collection or processing results in harm, for example by causing financial damage (e.g., by identity theft),205 reputational damage (e.g., through the dissemination of embarrassing information),206 physical harm,207 or discrimination.208
Liability rules would avoid the problems of property rules identified above. Liability rules are transactional rules that are useful when transaction costs are high.209 And the information asymmetry between data subjects and companies operates as a transaction cost: as a consequence, data subjects face information acquisition costs that make it difficult for them to reach welfare-enhancing transactions.210 As discussed in Part III, data subjects are likely to undervalue their data because they cannot know the magnitude of the potential risk.
Property rules’ ineffectiveness due to asymmetric bargaining positions would be remedied by liability rules’ ex-post compensation—which operates as collectively defined, as opposed to individually defined, “prices.” Defining compensation ex-post based on harm maintains compensation for the risks that data subjects are exposed to; in contrast, defining compensation ex-ante based on bargaining would be costly and ineffective due to asymmetric information and unequal bargaining power. Indeed, the standard rationale for suggesting the use of liability rules over property rules as a transactional rule is the high cost of ex-ante bargaining.211
The collection, processing, and dissemination of people’s personal information involve several parties, many of whom are unidentifiable ahead of time because they only come into contact with the data ex-post. Negotiating over one’s information would have exorbitant transaction costs—even when the costs of surveillance and communication are low.212 The relevant costs to determine which transfer rule best protects privacy rights in each context are the transaction costs of self-protection and obtaining agreement on the transfer and the price, not the costs of surveillance or communications. In other words, even if the information and power asymmetries did not exist, the costs of bargaining over personal data would be too high because people would have to bargain with countless parties. Coupling both problems makes bargaining and control over personal information impossible.
Fixing damages in accordance with the harm caused also addresses property rules’ problem of under-protecting inferred and re-identified information.213 Aggregation, as seen above, is a problem for property rules’ effectiveness: the information that is most relevant is not the disclosed information that property rules cover but aggregated information, including the inferred information made possible by such aggregation, which property rules do not cover. Under data property, data subjects would receive no compensation for harm produced by aggregated and inferred information—which is most harm. Liability rules overcome this problem because they can set compensation equal to the harm. Conversely, the expected cost of liability rules from the industry side would be equal to the expected cost of harm rather than the bargained-for price.
Due to that, moreover, an ex-post compensation would correct the moral hazard problem by varying compensation according to levels of care through liability. If data collectors’ cost of processing data was not fixed ex-ante by what data subjects agreed to, but rather ex-post by the harm produced to them, the externalities introduced by moral hazard would be internalized because companies would have to take risk into account to minimize their own liability. In other words, companies would have better incentives not to overprocess data and to invest in reasonable security measures because harming data subjects would become expensive.214 Liability rules correct moral hazard in an orthodox way: deterrence.215
2. Accounting for Consumers’ Risk Aversion
Besides addressing property rules’ gaps, liability rules present an advantage regarding risk aversion. Given that, on average, data subjects are more risk-averse than corporations, liability rules would be in the interest of both players in the interaction due to their ability to hedge risk.216 Under liability rules, not only are data subjects awarded compensation for harm but companies also face lower costs than in the impossible, hypothetical system where “perfect” bargaining can take place.
Recall Meyers and Kirchein, two cases about information collected in violation of FACTA that increased consumers’ risk of identity theft.217 What would have been adequate property-rule compensation for that information? That is, how much should each consumer have been paid to compensate them ex-ante for the risk increase? Someone could answer that the “price” should have been a monetization of the risk increase, considering both the cost of identity theft and the increase in the likelihood of an identity theft materializing as a consequence of the FACTA violation—the expected harm increase.218 But this answer would ignore that risk itself is often harmful or inconvenient to people.219 It is so beyond the expected monetary disutility that such risk may entail if it materializes. In other words, consumers are risk averse.220
If the amount of compensation is determined by the (ex-ante) expected harm, as such an answer suggests and one would expect it to be under property rules, risk aversion becomes an obstacle. People have disutility from risk that companies may not be willing to compensate. Even if a value for the data could be agreed to ex-ante (which, because of the problems above, it cannot) the value demanded by data subjects should be higher than the value offered by data collectors due to the risk averseness of the former. In other words, to adequately compensate data subjects ex-ante, companies would have to add compensation for the risk itself to the compensation for the expected harm—which they are unlikely to be willing to do. Because it avoids the disutility of risk, ex-post compensation—that is, being compensated for the harm once it happens, as opposed to being paid in advance for the expected harm whether it happens or not—is more valuable for data subjects than ex-ante compensation.221
Hypothetically, ex-ante compensation could take risk aversion into account and be set higher than the expected harm to account for the disutility of risk—leaving data subjects “indifferent” between ex-ante and ex-post compensation. But that permutation of property rules would be costlier than liability rules for data collectors. Even under the most expensive type of liability for companies—strict liability—liability rules’ expected cost would not exceed the expected cost of harm.222
Because compensation should be added for the disutility of risk under property rules, any type of liability—including strict liability—is cheaper for companies than a properly executed, non-exploitative property rule. Any industry argument in favor of property rules over strict liability necessarily relies on externalities imposed on data subjects. It relies on property rules, due to the problems explored above,223 being improperly executed.
The main objection to liability rules in privacy law is that privacy harm is difficult to detect and remedy.224 Liability rules introduce difficulties in determining compensation—and the indeterminacy of privacy harm makes this problem more significant.225 For example, when a website makes a ghost profile with someone’s name, but the data subject lacks evidence of reputational damage, as in Spokeo v. Robins, courts are unsure of whether to grant them remedy.226 Similarly, when a credit bureau is hacked but victims lack evidence that this has caused them financial damage, as in the Equifax hack, courts are unsure of whether to grant them remedy.227
While an in-depth exploration of this objection is carried out in a different article,228 two things are certain. The first is that, to the extent that privacy liability does not preempt public enforcement, investigation, and FTC penalties, a lower than efficient level of liability is still an improvement over no liability at all. Believing that almost no one will sue based on privacy is a reason to be less worried about implementing liability, not more. The second is that, for any level of privacy harm indeterminacy, privacy harm is easier for courts and enforcement authorities to identify ex-post than it is for consumers to anticipate and prevent ex-ante.
Any objection to liability based on privacy harm indeterminacy applies, magnified, to the property-rule-only model. Moreover, there are frameworks for assessing privacy harm ex-post that courts and regulators can use.229 But no regulator or adjudicator can anticipate this harm perfectly, much less consumers with insufficient information and no bargaining power. And the burden of anticipation adds the wrong incentives to take care ex-post when no such ex-post assessment is given.
A second objection is that relying on liability rules that depend on harm may run into problems of federal jurisdiction in terms of Article III standing according to the landmark standing case Clapper v. Amnesty International.230 This case law has received a fair amount of criticism. Thomas Haley, for example, has argued that federal standing analysis in privacy cases harms both public policy and standing doctrine.231 As Ari Waldman argues: “We live in a legal environment in which privacy rights mobilization is already difficult; managerial privacy compliance exacerbates the problem. Standing requirements and other hurdles hamper privacy plaintiffs’ use of tort law, contract law, and federal privacy statutes to vindicate their privacy rights.”232 In an ideal world, the moral hazard problem and the consequent centrality of liability for privacy protection should lead federal courts to revise and expand standing doctrine for privacy harms.
In the meantime, state courts have enormous power to hold corporations accountable for harm. Some of the most consequential privacy cases have come from state courts. For instance, in Rosenbach v. Six Flags, the Illinois Supreme Court ruled that an individual need not allege an injury beyond violation of her rights under the Illinois Biometric Information Privacy Act to be considered an “aggrieved” individual.233 The role of state courts in privacy will continue to grow as state privacy statutes introduced across the country become law. Privacy liability could function adequately while depending entirely on state courts.
B. How to Implement Privacy Liability
1. Liability Rules as Private Rights of Action
This Part has so far shown that, to protect privacy rights meaningfully, privacy law should include more robust liability rules in its combination of property and liability rules. The smallest change that would achieve this is keeping consent-based (i.e., property-rules-like) safeguards while enhancing the scope of private rights of action and compensable harm.
Incorporating liability rules for personal information can be achieved by creating a separate, harm-dependent private right of action in privacy statutes, such as the CCPA and Virginia’s CDPA. Similar liability is in place for data breaches and lack of data breach notifications,234 where plaintiffs litigate financial losses, emotional distress, costs of preventing future losses, and increased risk of future harm, among other claims.235 Data security, indeed, is built on flexible reasonableness standards that operate ex-post,236 which operate as liability rules. Such an approach can be expanded to privacy harm beyond data breaches.
Liability rules can also be created absent legislative reform. Courts can do so through the expansion of the privacy tort to complement statutory provisions.237 The judiciary can achieve this by doing two things. First, by expanding the interpretation of intrusion upon seclusion and public disclosure of private facts to include harm produced by conduct that is usually in the domain of statutory regulation.238 Second, by interpreting privacy statutes such as the CCPA and Virginia’s CDPA as not preempting privacy torts.
This system would not be unique to privacy. It is common practice for administrative and tort law to be combined to prevent and compensate harm. For example, environmental law bodies sanction companies for throwing prohibited materials into a river or building with asbestos without having to prove harm because the conduct was prohibited by administrative and environmental law. Meanwhile, victims of environmental harm have a private cause of action to sue these companies for harm they have incurred.239 State traffic law authorities, similarly, sanction individuals for driving with a broken light even when they did not get into an accident because of it—and one can sue when injured in an accident.240 None of these administrative regulations preempt compensation when harm occurs.
Courts interpreting privacy statutes can similarly make room for FTC sanctions for processing personal information without justification, as stipulated by applicable statutes, while giving individuals a common law remedy to obtain compensation when harmed. Abroad, in the European Union and adequacy countries, privacy law would complement data protection authorities’ sanction power in a similar way to how regulatory bodies of environmental and antitrust law are complemented in their ex-officio approach to give way for people to act.241 Both domestically and abroad, this would complement statutes that are focused on prohibited behavior with private law lawsuits focused on harmed individuals.
In terms of legislative reform, statutes can help overcome the difficulties that courts face by (i) making an explicit choice against tort preemption and (ii) providing guidance on how privacy harm should be estimated. No privacy statutes, passed or proposed, do this yet.242
After determining how to approach compensation under liability rules, the next question for their implementation concerns which type of liability is the most appropriate for privacy: negligence, strict liability, or something in between (such as comparative negligence or strict liability with a negligence defense).
2. The Appropriate Standard: Negligence Versus Strict Liability
In privacy, potential tortfeasors (data collectors and data processors) are the only parties in the interaction that can exert significant control over the probability of harm occurring and, if it does occur, the amount of harm.243 This is unlike most types of accidents governed by tort law.
Liability rules aim to place the burden of care on the party who can best control the probability of the accident taking place.244 An accident taking place depends on two things: levels of care (e.g., how attentively you drive your car) and levels of activity (e.g., how often you drive your car).
Negligence rules’ comparative advantage over strict liability is that they induce an appropriate level of care from the victim and tortfeasor (but not activity), while a strict liability rule’s advantage is that it induces an appropriate level of both care and activity by the tortfeasor (but not the victim).245 While strict liability has the advantage that it can incentivize an adequate level of care and activity from the potential tortfeasor, negligence has the advantage that it can incentivize an adequate level of care by both parties—but not an adequate level of activity.246 Tort law’s deterrence tradeoff is that negligence fails at inducing appropriate levels of tortfeasor activity and strict liability fails at inducing adequate care or activity from the victim.247 Therefore, from a deterrence perspective the question about which rule is most appropriate is a question about whether the accident is bilateral (its probability is affected by tortfeasor and victim behavior) or unilateral (its probability is affected only by tortfeasor behavior).248
Strict liability sets incentives for care and activity by the tortfeasor when the victim cannot affect the probability of the accident because the externality of the accident is internalized by liability.249 If harm occurs, under strict liability the tortfeasor has an obligation to remedy the harm no matter how it took place.250 Thus, tortfeasors are more likely to take expected harm into account under strict liability than they are under any other liability regime, in which only under certain circumstances will they be held responsible for the harm.
Such incentive-setting is relevant for resolving moral hazard. As explained in the context of product liability:
[I]f manufacturers have more control over the safety of their products than customers [do], the insurance [that] the consumers provide to manufacturers (in the form of limited liability for products’ accidents) would present a greater moral hazard than would the insurance that manufacturers provide to consumers (in the form of liability for those accidents).251
In technical terms, privacy harm is produced in unilateral accidents.252 After data are disclosed, data leave the data subjects’ sphere of control, thereby also rendering them unable to control the probability of harm.253 The protection mechanisms that data subjects can use after data are disclosed have a negligible influence on the probability of data harms compared to the security measures that data processors can implement.254
In addition, both the level of care and the activity levels of corporations are relevant for the probability of data harm materializing.255 The types of processing and level of database security (care level), as well as the amount of processing and number of data transfers (activity levels), affect the probability of data subjects being harmed.256
This is important for the choice of liability rule. The application of a negligence standard to liability for data breach notifications,257 and for data security generally,258 has been attacked on the basis that the correct level of due care may be uncertain, leading databases to overinvest in care. An ambiguous negligence standard would indeed introduce costly uncertainty.259 Providing victims with compensation without having to prove corporations’ negligence, as Danielle Citron explains, “would force database operators to internalize the full costs of their activities.”260 From an incentives perspective, a strict liability rule makes it easier to define expectations than does a property rule. This reflects the principle that liability rules are more efficient than property rules, even without prohibitively high transaction costs, when transaction costs stem from imperfect information.261
Unlike strict liability, negligence incentivizes appropriate care by the victim but, in unilateral accidents such as privacy harms, the victim’s care is irrelevant. This fact makes strict liability advantageous for privacy claims. For these reasons, a strict liability rule would internalize the externalities of moral hazard and induce appropriate levels of care and activity more effectively than negligence would.
C. Combining Public Enforcement with Private Claims
1. Rocky Statutory Precedent for a Mixed Enforcement System
Privacy lawsuits are not new.262 In the past, privacy problems were addressed through tort law: people sued when someone opened their letters, went through their financial papers, or disclosed harmful secrets to others.263
In most of statutory privacy law, however, it does not matter whether a victim was harmed, but whether a company behaved in a way forbidden by the regulation (ex-ante).264 This mechanism has benefits. Coupled with an enforcement authority’s investigatory powers, it can produce large-scale deterrence and it can address too-dispersed externalities and harms to public goods, such as the harms to democracy seen with the Cambridge Analytica scandal.265
However, it is difficult to achieve compensation—together with large-scale deterrence—when fines are prioritized as an enforcement mechanism. Public regulatory enforcement by itself cannot sufficiently provide victims with compensation.
Similarly, deterrence is better achieved by a mixed system. The FTC has referred to information asymmetry, coupled with language of market failures, to promote regulatory intervention independent of data subject consent in legislative reform.266 But both public and private enforcement are needed in practice to overcome the information and power asymmetries that exist in personal data collection, processing, and use. In other words, together with public enforcement by state attorneys general that comprehensive state statutes such as Virginia’s CDPA, Nevada’s PICICA, and the Colorado Privacy Act contemplate,267 private rights of action are key for achieving citizen and consumer data protection.268
Other state privacy statutes give rise to private rights of action allowing for such a mixed enforcement system. Some examples are Washington D.C.’s Use of Consumer Identification Information Act,269 and Illinois’s Biometric Information Privacy Act.270 The latter famously triggered the lawsuit against Six Flags271 and, more recently, a class action lawsuit against Clearview AI for building one of the largest facial recognition databases in history.272 The CCPA creates civil penalties and a type of private right of action for statutory violations that gives consumers some ability to bring claims related to data security breaches (for actual or statutory damages, whichever is greater),273 although it lacks private rights of action to enforce most of its elements.274
Abroad, private claims are less straightforward as they are usually based on provisions that make it difficult for individuals to bring even deserving claims successfully. For example, in Canada, starting a claim under the Personal Information Protection and Electronic Documents Act is a long process: individuals must first report it to the Office of the Privacy Commissioner, wait for the office to investigate and release a report, and then start a de novo application in court.275
While foreign cases based on statutory privacy are, as a consequence, infrequent, some precedent does exist. The GDPR stipulates, in this regard, space for private rights of action. Article 79 (right to an effective judicial remedy against a controller or processor) and article 82 (right to compensation and liability) contemplate the possibility of data subjects initiating actions to obtain redress, including material and immaterial harm.276 As of today, almost all precedent on this front stems from behavior that breached the GDPR and produced material harm, with immaterial harm having virtually no traction in courts, and both material and immaterial harm without a statutory breach not being contemplated.277 Ultimately, article 82(1) offers an ambiguous statement of claim for compensation that contributes to confusion when implemented by national courts.278
Reception varies by jurisdiction because the courts of Member States determine the scope and meaning of “material and non-material damages” and how much compensation is appropriate for them.279 Traction has mainly taken place in The Netherlands,280 Germany,281 and Austria.282 The United Kingdom, similarly, has seen cases in small claims courts based on article 22 of the Privacy and Electronic Communications Regulations 2003 when a corporation acts in breach of the regulation, particularly when collecting information absent a lawful basis for processing.283
2. Liability Must Depend on Harm
These private rights of action are the paradigmatic type of liability-rule protection over privacy rights. In a property-rule-only system, these would not exist, as it would only matter that the right is transferred with consent. However, instantiations of liability rules in current regulations are mostly limited to private rights of action for breach of the regulation, as opposed to private rights of action for the occurrence of harm. In terms of the normative considerations set above, this mechanism can be read as a liability rule with a negligence standard, where compliance with the regulation is due care that exempts from liability.
For liability to be most effective, private rights of action must be based on harm, not based on regulatory breach. This is so because of the moral hazard problem explained above. Creating a private right of action for breach of the regulation doubles down on consent and control, simply adding private enforcement. Doing so may be effective as a means of reducing public resources needed by the FTC and data protection authorities abroad, but it does not change the nature of the rules: companies can still pay attention only to the behaviors mandated and ignore whether they are producing harm. The only way to solve the moral hazard problem is to meaningfully enhance the role of liability rules in statutory privacy. And to enhance the role of liability rules is to create liability for harm created independent of whether it was a consequence of regulatory breach.
In other words, private rights of action based on harm will require companies to internalize externalities. Statutes like the CCPA that condition private rights of action on breach of regulated conduct and make them agnostic to harm do this wrongly. To be effective at protecting consumers, these private rights of action should, instead, depend on harm.
VI. Bolstering Use-Restrictions
As shown above, data property proposals aim to enhance something that privacy statutes have been doing all along: relying on data subjects’ control for them to protect their own privacy. The difference between existing law and data property is that the latter aims to achieve that objective solely through property rules, instead of doing it by mandating and prohibiting specific activities. But control through property rules is ineffective at avoiding harm. This is a reason to strengthen ex-post accountability in privacy law.
The second way of strengthening ex-post accountability in privacy law—besides private rights of action—is bolstering use-restrictions. The single, although modest, use-restriction present in statutory privacy is the purpose limitation principle. By creating an obligation that comes after the transfer and is independent of any agreement, purpose limitation takes privacy law a step away from relying solely on property rules. The usefulness of the purpose limitation principle is illustrative of why property transfer rules applied to personal data would not work. Purpose limitation is a way to mitigate, albeit marginally, moral hazard. At the same time, the moral hazard problem is informative of how privacy statutes should delineate purpose limitation.
A. The Usefulness of the Purpose Limitation Principle, Revisited
1. The Benefits of Prohibiting Purposes
Liability rules cannot solve all privacy problems. Liability cannot even solve all consent-produced privacy problems when coupled with public enforcement. Many harms are too dispersed. Some of them can be addressed through privacy class actions.284 But how would the law internalize social externalities such as harms to democracy? It is impossible to constitute a class for social harms.285
Privacy law needs accountability mechanisms that address these harms. To address them, privacy law is improved by mandatory rules (provisions that cannot be waived by agreement) that set external boundaries over what corporations can and cannot do. A fraction of European-style data protection law abroad focuses on doing this: it sets mandatory rules determining what companies cannot do even after acquiring consent. For example, under the GDPR, companies cannot seek individual consent to avoid having a data protection officer, or not give explanations when the right to an explanation is triggered. These are mandatory rules that apply independent of agreements between individuals and companies. These rules exist in opposition to default rules, such as the prohibition of third-party sharing, which individuals can override by agreement, and in stark opposition to data property, under which individuals can endorse any activity.
Purpose limitation broadly construed (that is, the idea of limiting an entity’s use of information for specific purposes) is an important mandatory rule because it focuses on ongoing uses. The role of this broad, conceptual purpose limitation is to limit (prohibit) certain purposes—those that are particularly risky, or not likely to be in the best interest of data subjects. A prohibition of certain purposes, while new for American privacy law, would be uncontroversial in other areas of the law. The law frequently prohibits risky uses of otherwise allowed entitlements.286 For example, in most states, people have the right to purchase a firearm but they cannot shoot their firearm in public. This limits the use of firearms: to use them lawfully, people in those states must fire them in a shooting range.
One could ask based on this: do principles such as data minimization and necessity share this characteristic?287 The answer is yes to the extent that they are mandatory rules. But they have one relevant difference in that they do not prohibit purposes. These principles reduce risk in a harm-focused manner but, because they are ex-ante, they do not address moral hazard like prohibiting purposes or setting liability rules do. Instead, these principles reduce risk by reducing companies’ options.
The diluted version that exists in privacy law of that broad, hypothetical, and robust purpose limitation is the purpose limitation principle. Although it does not prohibit any particular purposes, the principle prohibits using personal data for a new purpose or collecting personal data for undeclared purposes. Because it does not limit possible purposes but it mandates their specification, it could be more accurately called purpose specification principle, as some statutes do.288 The law should, at least, maintain and bolster this minimal limitation on ongoing use.
Incidentally, a reader could ask: if purpose limitation were to be violated, what would be the remedy? The answer is liability. A corporation that breaches purpose limitation, depending on the enforcement system, may have to pay a fine if subject to public enforcement or monetary damages if subject to a private right of action. This is where both proposals converge.289
2. Purpose Limitation’s Standard Rationale
The purpose limitation principle is drawn from the Fair Information Practices Principles, which are the backbone of American privacy law.290
Purpose limitation is one of the key provisions of the CCPA, the California Privacy Rights Act, Virginia’s CDPA, and the Colorado Privacy Act. The CCPA adopts this principle when it requires purposes “compatible with the context in which the personal information was collected.”291 It is also included in Virginia’s CDPA when it prohibits businesses from “process[ing] personal data for purposes that are neither reasonably necessary to nor compatible with the disclosed purposes for which such personal data is processed, as disclosed to the consumer, unless the controller obtains the consumer’s consent”292 and by the Colorado Privacy Act when it requires controllers to “specify the express purposes for which personal data are collected and processed,” and prohibits “purposes that are not reasonably necessary to or compatible with the specified purposes for which the personal data are processed.”293 But, far from being an obvious inclusion in states’ privacy statutes, purpose limitation is not included in Nevada’s PICICA,294 and proposed state bills have been divided on its inclusion.295
Abroad, purpose limitation is a key provision of the GDPR and of privacy legislation in countries that have or seek GDPR adequacy status.296 Purpose limitation is required by the GDPR by articles 5(1) and 6(4).297 Article 5(1)(b) establishes the need to delimit purposes anchored on a lawful basis for processing. Article 6(4) authorizes further processing for a new purpose only when compatible with the one for which the personal data was originally collected.298 Further data processing requires a new lawful basis for it to be justified; that is, one of the legal grounds required to authorize the initial processing.299
These GDPR provisions are relevant to American law. The GDPR is relevant to American companies as well: since the Schrems II case from July 2020, they must also comply with the GDPR when collecting, processing, or distributing personal information from European data subjects.300 The GDPR has also influenced state statutory privacy, such as the CCPA and CDPA, and will likely influence future state and federal privacy statutes.301
Identified purposes function as an obstacle for companies to obtain facile consent (i.e., consent that is not meaningful).302 Data protection agencies abroad often rule that data collection was unlawful because data subjects were unaware of the purpose for which their data were being collected. For example, in 2011 the Canadian Office of the Privacy Commissioner found that a complainant was uninformed concerning the collection of her personal information because its purpose was vague—and therefore she did not meaningfully consent.303 In 2014, it asked an organization to translate its policy because the complainant was uninformed concerning the collection purpose due to her limited understanding of English.304 By doing so, the principle reduces the asymmetric information and unequal bargaining power problems.
3. Purpose Limitation and Property Rules
The irony is that property rules in personal data are incompatible with a wide application of the purpose limitation principle. Property rules operate based on the transferability of the rights they protect,305 making it more difficult to impose any restrictions ex-post.306 Cohen pointed to this idea when arguing that property is incompatible with privacy because property is “grounded in a theory of self-actualization based on exchange—designed to minimize transaction costs and other obstacles to would-be traders, and thus systematically, inevitably biased toward facilitating trade in personally-identified information.”307
Notably, property rules allow for subsequent sales once information is acquired—as with any physical object that one can re-sell after buying.308 In this way, while property rules may appear consumer-protective, they lower transaction costs for subsequent sales, making risky third-party sharing easier for companies.309
Property rules keep transaction costs relatively low precisely because consent (to transfer a right) needs to be acquired once, and not again for reusing or reselling the entitlement that was transferred through consent.310 The purpose limitation principle removes this characteristic. The purpose limitation principle does so because it restricts what can be done with the information after a transfer, meaning that the company acquiring the information cannot use it or share it with another party without a new agreement to do so.311 Requiring companies to ask data subjects for permission each time such information was traded keeps transaction costs higher than with property rules.312
By removing the property-rule characteristic of acquiring consent only once, the purpose limitation principle reduces moral hazard in two ways. The first way is that it reduces the information asymmetry between consumers and companies. Moral hazard arises partly because of such information asymmetries.313 By increasing transparency about the uses that can be given to information, a source of uncertainty is removed because the levels of ex-post risk are partly determined by new, risky uses. This method is orthodox for addressing moral hazard in consumer law, as is done through warranties, which reduce uncertainty about products’ durability.314
The second way is that it generates ex-post accountability. Such ex-post accountability reduces moral hazard between companies and consumers because it places ongoing use restrictions on personal data. The purpose limitation principle does not eliminate moral hazard, as companies can still use and share personal data in risky ways without internalizing such risk. But the scope of possibilities becomes more limited. Reducing the scope of behavior from the more-informed party, as the purpose limitation principle does, is a way to reduce moral hazard in economics.315
Ultimately, specifying purposes in advance mitigates the problems identified above, even if it does not solve them entirely. Because purpose limitation is a well-tried principle already embedded in American law, it is a low-cost intervention that can, at least in part, mitigate the moral hazard problem.
B. Property and Liability in Purpose Limitation
1. (Limited) Lessons from Intellectual Property
This last point relates to the difference between ownership rights and property rules explained above. While, in ownership over real or personal property, rights are often transferred in their entirety—meaning that the new owner can do with it what she desires316—this is not the case for all other ownership-similar types of rights. Ownership-similar rights, such as intellectual property rights, are protected by a mix of property and liability rules.317
Take the example of copyright. Regarding the property characteristics of copyright law, authors holding copyright are entitled to exclude others from copying their work.318 The holders can either transfer copyright in its entirety or (more frequently) grant a license for the use of their work in exchange for a royalty,319 partially alienating their rights to exclude and to request injunctions for the breach of such exclusion.320
Regarding copyright’s liability characteristics, authors face some compulsory licenses and must accept fair use.321 While compulsory licenses tend to be specific and limited, fair use is a central trait of copyright law.322 Purpose limitation, which allows for ongoing use-restrictions as opposed to permanent transfers, finds analogs in copyright law.
Like other liability rules, fair use is justified by high transaction costs. Specifically, by the high transaction costs that would otherwise be incurred in negotiating and monitoring the uses that it protects.323 For example, the law allows quoting scientific works without the author’s permission arguably because obtaining such permission every time would create exceedingly high transaction costs, while citations do not harm the author’s economic interest.324 If the quotation is large enough to cover and thereby substitute for the whole work, on the other hand, it would harm the author’s economic interest, and the law requires permission to do so.325
Compulsory licenses, similarly, are a liability rule designed to facilitate non-consensual use of an entitlement: them being compulsory means that the right-holder has no choice over the transfer.326 Compulsory licenses are often set at actual damages (or an estimate of how the entitlement would be priced in a market transaction), which allows for their use as long as it is efficient for users to pay that collectively determined price.327 Compulsory licenses under copyright law are analogous to the purpose limitation principle. Both specify the objective for which the information can be used and forbid its use for other purposes.
An argument can be made in favor of liability rules in privacy law based on this similarity.328 This is not to say that privacy law should be part of or further resemble intellectual property law. This has been shown to be incompatible due to the different aims of intellectual property law and privacy law.329 What the analogy does, rather, is show that some of the most protective features of privacy law, such as the purpose limitation principle, are not based on property rules and, moreover, are incompatible with enhancing the role of property rules.330 The intellectual property analogy can illustrate, in other words, why it is undesirable to be concerned exclusively with information’s initial transfer, like data property advocates are.
2. Purpose Limitation’s Liability and Market Failures
Because of its liability rule characteristic of operating ex-post, the purpose limitation principle mitigates the problems of asymmetric information, unequal bargaining positions, and unprotected inferred data. The prohibition on asking consumers to agree to the use of data for any purpose is a limit on contractual freedom that mitigates the unequal bargaining positions problem. It marginally reduces asymmetric information because it establishes that companies will not use the data for unknown purposes. It reduces the problem of inferred data because it poses limits on corporations’ ability to create more inferred data.
An example of purpose limitation being used for these aims exists in the GDPR. GDPR purpose limitation prohibits bundling consent, which is a way for corporations to abuse bargaining power and information asymmetry.331 Since inferences constitute a new purpose, purpose limitation is a useful tool to prevent the unexpected aggregation of information into new information about consumers without their knowledge.332
Here a reader might wonder: Seeking authorizations from data subjects for each secondary use of information would increase transaction costs, especially given that personal information is valuable when aggregated—and that processing involves many data subjects. Is the purpose limitation principle not, then, a property rule, to the extent that it enhances exclusion? Fair use means that one can use someone else’s copyrighted work without their consent, but purpose limitation means that to use someone else’s personal information one needs further consent. Why is this further consent not property-rule-compatible?
The difference lies in who holds the right. In fair use, for example, the author holds the copyright-created right. Using it without acquiring consent is replacing a property rule with a liability rule. In purpose limitation, after having collected information under a lawful basis (and potentially compensating the data subject) under property rules the corporation would hold the right and could therefore do with the right as it sees fit. The purpose limitation principle shows that not all privacy rights are transferred by data subject consent, as they would be under data property, because data subjects retain rights over that information. Data property would eliminate such protections.
C. Purpose Limitation Reform
Based on what was argued above about the importance of the purpose limitation principle and how it interacts with property and liability rules in privacy, law reform proposals can be developed to make the purpose limitation principle more effective at addressing moral hazard.
First, legislative reforms could require that the stated purpose must be specific.333 This is the case under the GDPR.334 As Hoofnagle explains, “vague and abstract purposes such as ‘promoting consumer satisfaction,’ ‘product development’ or ‘optimizing services’ are prohibited.”335 But several other jurisdictions allow for vague purposes.336 The proposal to incorporate this requirement may carry extra weight for countries seeking to acquire or maintain GDPR adequacy status.
In jurisdictions that lack this specificity requirement, identified purposes not found in breach of this provision and considered sufficiently limited have included statements as broad as “workforce productivity” or “market research.”337 Those purpose formulations can be helpful for organizations, but not for data subjects. A reframing of purpose limitation with the objective of informing data subjects about the aims of the data collection, processing, and dissemination would better mitigate the asymmetric information and bargaining power problems.
This change could be implemented through statutory reform in proposed bills by adding the specificity requirement in purpose limitation provisions, but it can also be implemented without law reform. The CCPA, the California Privacy Rights Act, the Colorado Privacy Act, and Virginia’s CDPA all include the purpose limitation principle broadly (without explicitly requiring specificity).338 The specificity requirement could be implemented by the enforcement authorities, such as state attorneys general, that must interpret the statute when enforcing it. These authorities could (and should) take the opposite route of authorities abroad that have accepted wide purposes like “workforce productivity” and “market research.”
A second recommendation is for enforcement authorities to develop a standard for assessing when use or dissemination constitutes a new purpose. Such a standard would, in turn, determine when use or dissemination must be communicated to the data subject with a new request for consent.339 This standard can be created by legislators engaged in statutory reform or by enforcement authorities.
One way to conceive such a standard is by implementing a reasonableness standard.340 It would ask: “did the data subject have a reasonable expectation that consent would be re-acquired for the subsequent use or dissemination?” A reasonableness standard for purpose limitation would stand in contrast to private law standards in most other technical contexts, such as standards in professional responsibility.341 The explanation is that this standard would primarily aim to reduce the information asymmetries that magnify moral hazard, rather than to increase verifiability for facilitating the determination of liability, as professional responsibility standards do.
This standard would fit under the principle in privacy law of considering people’s reasonable expectations of privacy.342 Although one could fear that technical aspects would be a poor fit for this reasonableness standard, the standard would be compatible with a data-subject-focused purpose limitation principle that aims to reduce moral hazard. A reasonable person standard would be closer than a technical standard to the idea that the purpose should be specified to data subjects in understandable terms.343
If enforcement authorities care about reducing moral hazard, in other words, they have good reasons to mandate purposes to be specified in writing for data subjects, not for regulators, so as to increase certainty and foreseeability.
The third recommendation that stems from the failings of data property is to include prohibited purposes. This is a more significant deviation from current law. Until this point, this Part argued for implementing the purpose limitation principle in proposed bills by requiring that specific purposes are disclosed at the moment of data collection. As mentioned, specifying purposes is the smallest possible intervention that is helpful for mitigating the moral hazard problem. Prohibiting purposes that are considered particularly risky is a more ambitious permutation of the same principle.
Prohibited purposes are the missing element of purpose limitation that can maximize its potential for creating ex-post accountability. Included under the broad idea of purpose limitation, this measure would identify specific uses for personal data as too risky. Instead of having individuals (or the market) decide which purposes are acceptable, these purposes would be identified through the political process. It can thus be seen as a collective, rather than individual, purpose limitation.
Beyond purpose limitation, data protection law abroad sometimes desirably engages in more substantive ongoing use-restrictions by prohibiting certain uses or purposes that may be highly risky for data subjects. A recent example of this—although technically outside data protection law—is the proposed European Union’s A.I. Act.344 The Act is structured by risk, prohibiting some uses of AI that are considered the riskiest, such as social scoring in the public sector and facial recognition for law enforcement with exceptions.345 Interestingly, the Act includes a harm requirement in the prohibitions, stating that it is for an activity within the specified parameters that “causes or is likely to cause that person or another person physical or psychological harm.”346 Such probabilistic harm requirement (while it could be criticized for limiting the provision’s scope) is illustrative of the link between ongoing-use restrictions and liability rules because it makes explicit that such ongoing-use restrictions are designed not to maximize control but to prevent harm.
The advantage of incorporating prohibited purposes is that doing so frees data subjects from having to self-manage purpose-related choices, on which they continue to have asymmetric information and unequal bargaining power. It avoids placing the burden on data subjects to make risk-reducing choices at the moment of data collection.
In the language discussed here, such a reform of the purpose limitation principle would take it further away from property rule protection (dependent on consent) and towards liability rule protection (dependent on collective mechanisms).347 Private rights of action, moreover, are fully compatible with such a mechanism. Individuals could still seek redress individually; they would just do so for actions that were determined to be wrong by the political process, not the market.
Conclusion
Data property proposals are widely misunderstood, aim at the wrong goal, and would be self-defeating if implemented. Policy, media, and academic proposals to protect privacy with property abound. These proposals do not aim to create ownership rights over data; rather, they propose protecting existing privacy rights with what Calabresi and Melamed call property rules.
In other words, data property proposals do not propose mutating the content of privacy rights but rather ensuring that these rights are transferred solely by consent and in exchange for an agreed-upon price. The first portion of this Article is thus corrective: when people argue for “property over data,” they are arguing for “some kind of right over data, not necessarily a property right, that is protected by a property rule.” This means that, to refute the proposal (as typically stated) that “people should have property over data,” one’s target should be the claim that “people should have some kind of right over data, protected solely by property rules.”
These property rules produce problems specific to privacy. The second portion of this Article shows the flaws in data property that make it inadequate at protecting privacy rights. Data property proposals leave out important dignitary considerations, ignore asymmetric information and unequal bargaining power, and fail to address the harms produced by aggregated and inferred personal data. These problems indicate that data property bolsters the wrong protection mechanism.
But data property has an additional problem that defeats its own goal of guaranteeing individual control. Privacy harm can be produced at the moment of collection, processing, or dissemination of personal information. And property rules can only control the moment of collection. By condensing protection guarantees to the moment of collection (in property terms, exchange for a price), property rules produce a moral hazard problem: unless otherwise constrained,348 companies lack incentives to minimize processing and disclosure harms after the exchange has taken place. This means that data property not only has the wrong goal (control), but also fails to achieve that goal.
This finding does more than provide a normative reason not to implement data property. It also provides insights for privacy law reform. Statutory privacy reforms should complement their property rule elements with liability rules. This Article explores two ways to do this. The first is allowing for private rights of action. For them to reduce the moral hazard problem, private rights of action must be orthogonal to the basis for collection and depend on the creation of harm, irrespective of how such harm occurred. The second is reinforcing use-restrictions, particularly the purpose limitation principle. While purpose limitation improves consent, it ironically contradicts property rules by placing limitations on use and disclosure after the exchange.
Without statutory reform, both proposals can be advanced by courts. Regarding the first, there is value in interpreting privacy statutes as (i) including liability rules and (ii) not preempting tort law claims, thus using tort law as a complement to statutory privacy. Regarding the second, courts could interpret the specificity of purposes more narrowly than they currently do, ruling that too-broad purposes (such as “marketing purposes”) breach purpose limitation. So could enforcement authorities such as state attorneys general and the FTC.
Legislators and enforcement authorities should abandon the idea that property solves control problems in privacy law. Instead, they should underpin accountability mechanisms for privacy harm. All in all, it is crucial for privacy law to focus on what happens beyond the point of transfer, which is the only point that data property scrutinizes.